| url | title | original | self | post_date | comments | author | id | upvotes | content | comment_date | replying_to | subreddit |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Data Acquisition - Reddit
Introduction
Aside from reporting done by news media organizations, Student Loan Forgiveness is a toipc on social media and public discussion platforms such as Reddit. Reddit consists of communities known as Subreddits, where users can participate in topic specific online discourse. Although some users choose to tag their accounts with political bias leanings such as liberal or conservative which could help determine sentiment on certain topics, this isn’t prevalent enough to use as a proper label. However, different sentiments and biases could be found for individual users and Subreddits. Additionally, interesting associations and networks could be formed between the users and communities.
Note that the terms “Reddit Users”, “Reddit Usernames”, and “Reddit Authors” will be used synonymously throughout this analysis.
Gathering the Data
To obtain the data from Reddit, web scraping and an API was utilized. A web scraping function was built which mimics a general search within the Reddit platform and returns the URLs for threads on a given search query. The URLs were then iterated through with the API, which returned the posts, comments, replies, and other supporting information.
Three search queries were made:
- Student Loan Forgiveness
- Student Loans
- Is a College Degree Worth It
However, Is a College Degree Worth It data may not be utilized, as it’s not as precise to the topic of this analysis.
Specific objects and tags were created with API calls, and ultimately returned as a dataframe.
Cleaning and Restructuring
The main cleaning that was required was for the content; posts, comments, and replies. The following processing occurred:
- If the first post on a thread returned blank, this likely indicated a link to an outside source. In this case, the title was used as the content.
- Values within the content strings such as line breaks and reply indicators were removed.
- Email addresses and links were removed.
- Emojis and other non-ASCII characters were removed.
- Duplicate posts were common and were removed.
This initial cleaning step still left the individual posts, comments, or replies as rows themselves.
Given that quite a few rows of content could be a few words, or even a single word reply, the idea for the next processing step was to have content from each author for each thread aggregated together. Additionally, data maps were created to track communications between authors. For each thread, the following restructuring was performed for a given author:
- Lists:
- Upvotes (can be positive or negative)
- Posting Dates
- Content (posts, comments, and replies)
- Replies To (who the author has replied to)
- Replies From (who responded to the author)
- Values for Specific Threads:
- URL
- Title
- Subreddit
- Author (Reddit username)
- Original Author (boolean for if the author started the thread - made the original post)
A sample of the Restructured Reddit data
| url | title | subreddit | author | original_author | author_upvotes | author_dates | author_content | author_content_aggregated | replies_to | replies_from |
|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Future Processing and Potential Labels
Similar to how content can be aggregated for each author per thread, a similar process can be done for an entire thread, an entire subreddit, or even aggregated for authors across mutliple threads.
Following this concept, potential labels could be search query, author, subreddit, or even popularity or approval of community by upvotes. Additionally, unsupervised methods such as association rule mining and clustering could be logical choices for examining this data. Associations and interactions may become apparent with these methods.
In relation to the two core views of supports and does not support student loan forgiveness, the NewsAPI politcal bias classification models could potentially be used to interpolate political bias for authors and Subreddits. Thus, author and Subreddit sentiment towards the topic could potentially be predicted. Another application could be to examine clusters and associations along with their classifications.
Reddit Authors
To proceed with the plans of analyzing the content of a specific Reddit user (author) as a whole, it could be useful to see if there is enough data for individual authors.
The restructured dataframes of the Reddit search queries Student Loan Forgiveness and Student Loans were combined. The idea is to look at the appearances of authors across three different scenarios:
- How many authors have multiple submissions in a single thread?
- How many authors have submissions in multiple threads?
- How many authors have submissions in mulitple Subreddits?
Top Ten Authors Across Scenarios
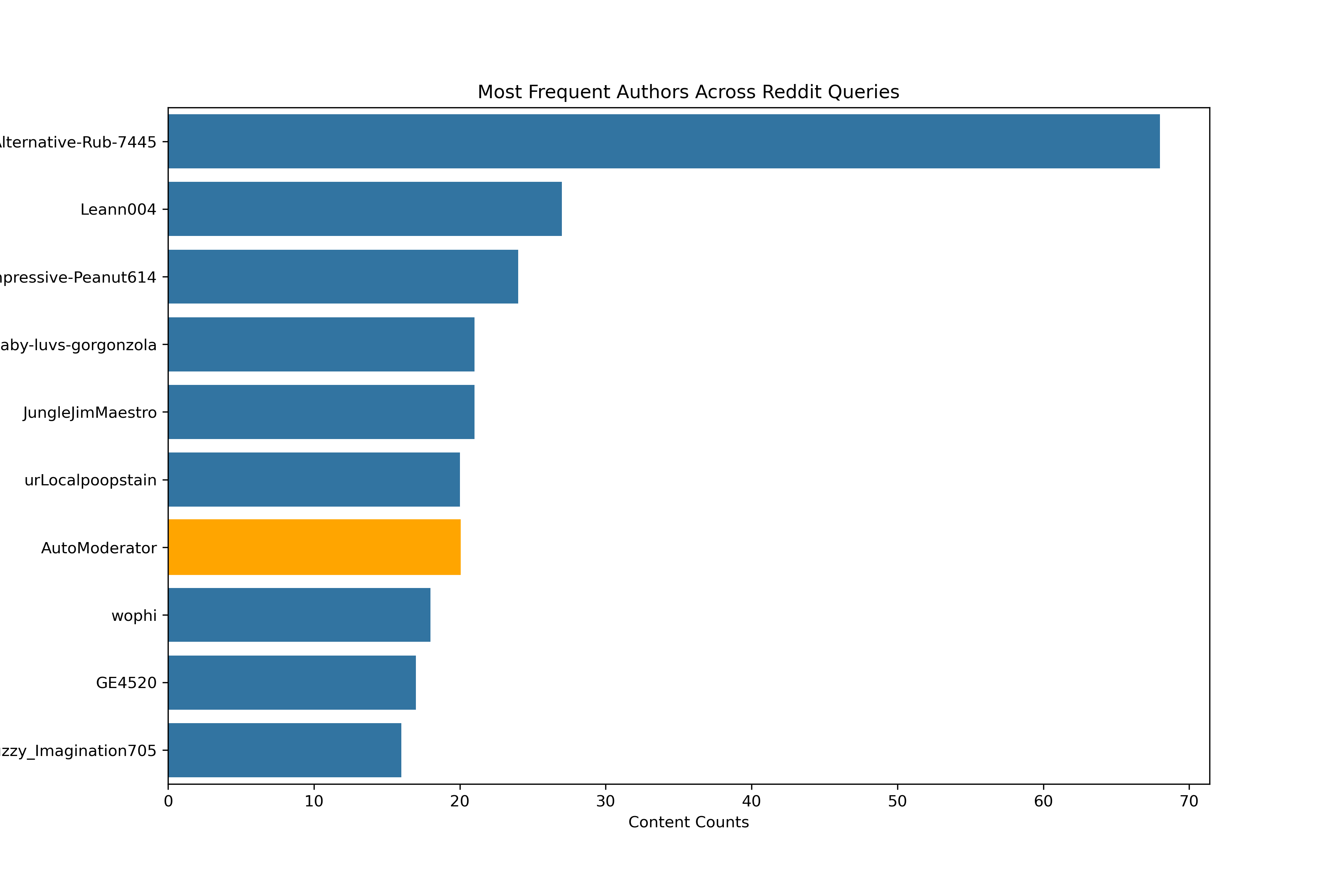
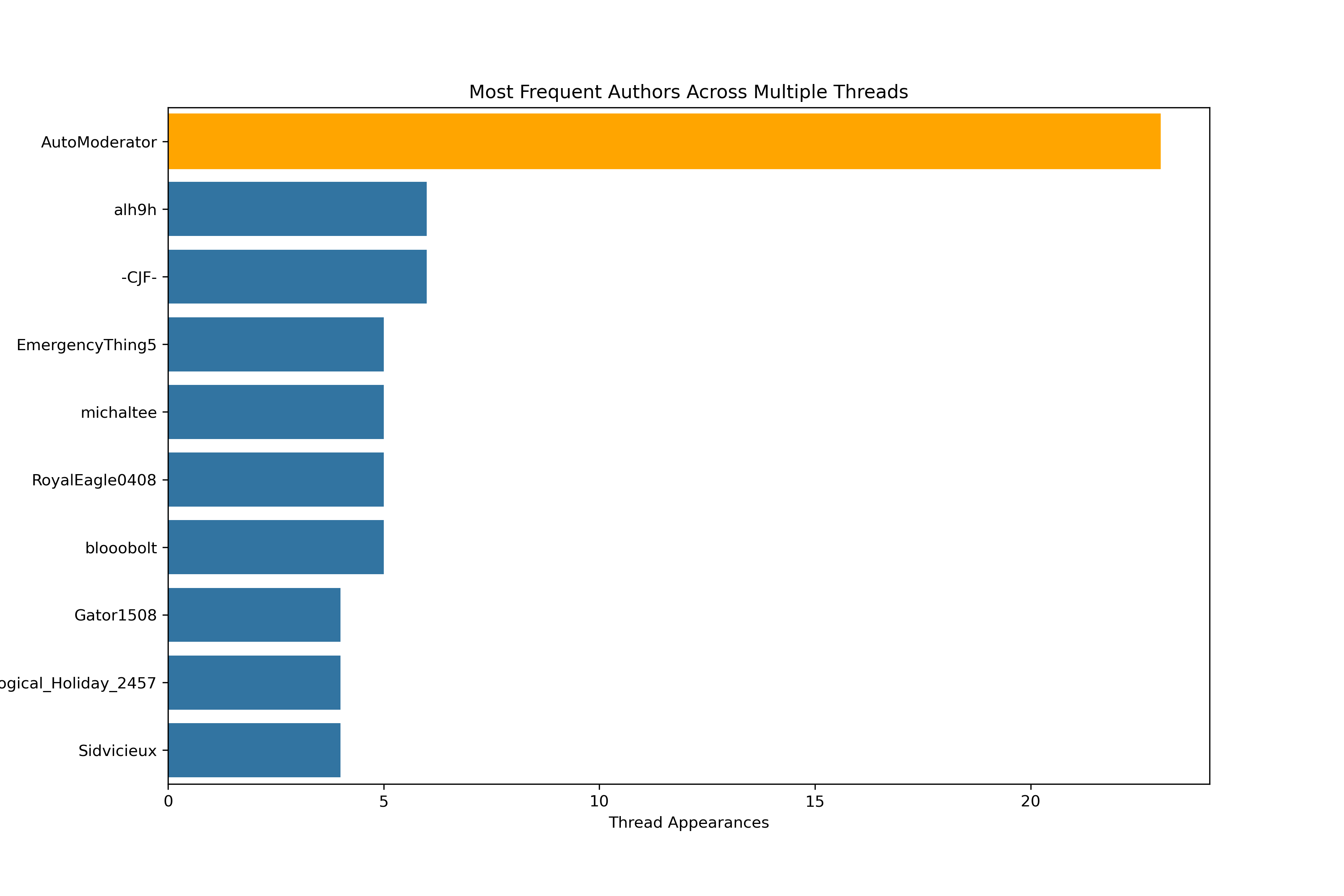
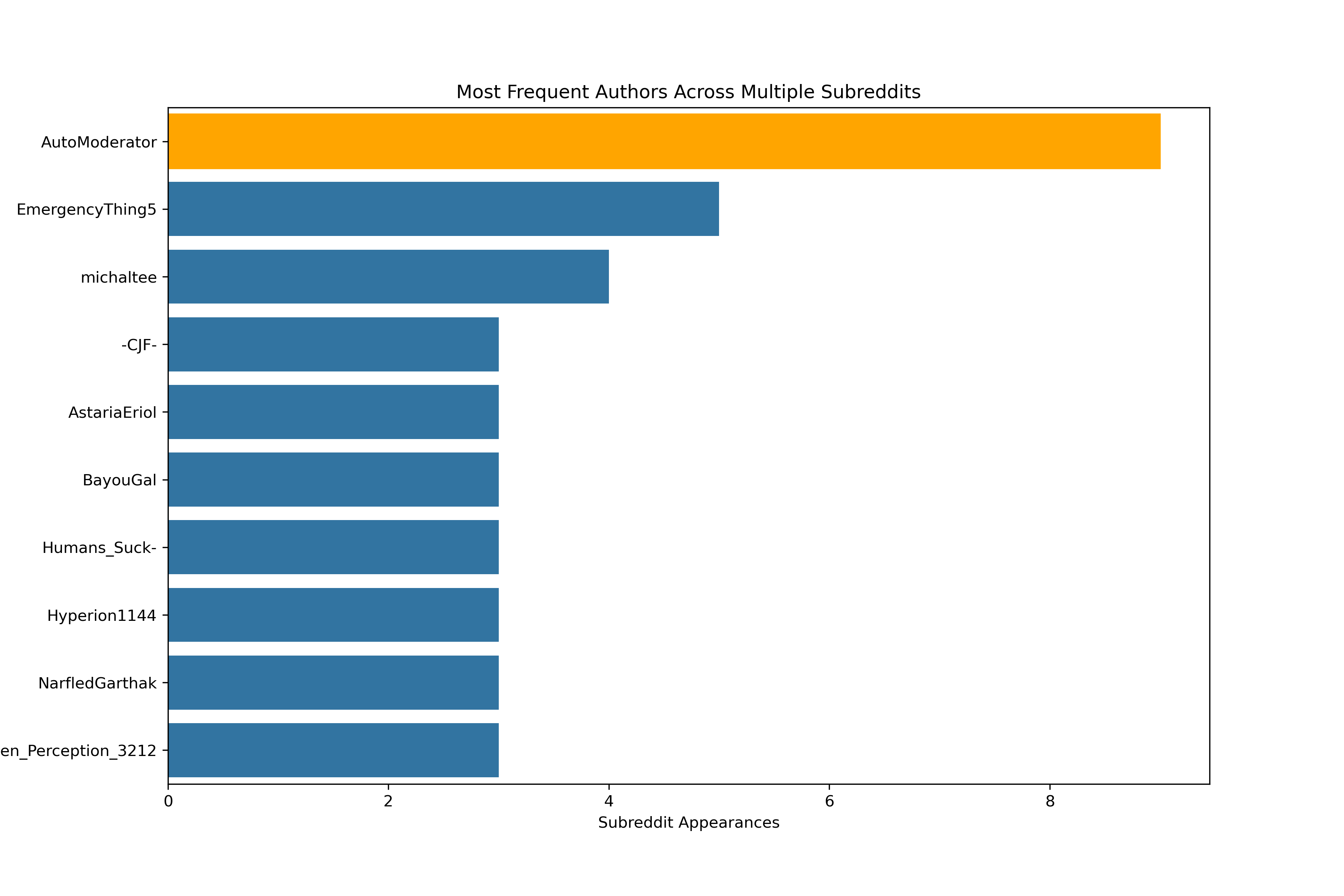
From left to right in the above images:
- Most Frequent Authors Across Reddit Queries: illustrates the top ten most frequent for the total number of posts, comments, and replies by author across all Reddit threads.
- Most Frequent Authors Across Multiple Threads: illustrates the the top ten authors who have at least a single piece of content in a Reddit thread.
- Most Frequent Authors Across Multiple Subreddits: illustrates the the top ten authors who have at least a single piece of content in a Subreddit.
There were a few takeaways from these illustrations. Although many authors only had a single appearance, there were a few who frequently post in these Reddit topic-specific communities. One user is actually a Reddit sanctioned bot, known as a Moderator, which helps to control inappropriate or misplaced discussion. This bot, AutoModerator, has its post shown in orange above and will be removed in the subsequent analyses.
Potential Aggregations
The authors are one point of aggregation, however, what are the numbers associated with all potential aggregations? Recall that content will be aggregated via authors, threads, and subreddits to analyze different sentiments. The illustrations above show some intersection between authors across the threads and communites, but the following table will show some count data overall:
| Category | Counts |
|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Code Links
- Reddit Extraction Script: script with functions and code to extract the necessary Reddit data
- Reddit Cleaning Script: functions related to cleaning extracted Reddit data
- Reddit Cleaning Application Script: application of the Reddit Cleaning Script