| url | title | subreddit | author | original_author | author_upvotes | author_dates | author_content | author_content_aggregated | replies_to | replies_from |
|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Vectorization - Reddit
Introduction
Using the data which has been prepared and merged with potential labels, as seen in Data Acquisition - Reddit, a few more steps can be taken to turn the Reddit posts into numerical representations which can then be used for further analyses and machine learning applications.
Strategy - Further Preprocessing
Recall that the prepared data looks like this:
As explained in the linked section above, the Reddit text data may be best fit for unsupervised learning methods, thus the labels may not be applicaple. However, potential labels of interest are:
- Author (Reddit user)
- URL (Reddit Thread)
- Subreddit (Reddit Community)
- Search (Reddit Search Query)
The data itself will be the content posted by the Reddit users, or authors. In the inital data above, the column containing every post, comment, and reply by an author on a single Reddit thread was aggregated. This will be the first aggregation schema. A few other aggregation schemas will be considered.
Aggregation Schemas:
- Thread - Author (INITIAL FORMAT): corpus where each file is an author’s aggregated text within a unique thread.
- Subreddit - Author: corpus where each file is an author’s aggregated text within a unique Subreddit.
- Threads: corpus where each file is the overall aggregated text within unique Threads (author’s combined)
- Subreddits: corpus where each file is the overall aggregated text within unique Subreddits (threads combined).
- Authors: corpus where each file is the overall aggregated text by authors across every thread.
Using the initial format for the first schema, some additional preprocessing will take take place for the author’s aggregated posts on a single Reddit thread. This will include:
- Remove line breaks.
- Remove punctuation.
- Remove words containing numbers.
- Remove standalone numbers.
- Remove leading and trailing spaces.
- Lowercase the remaining words.
- Remove any single-length text remaining.
As prescribed in the linked section in the Introduction on this page, the author AutoModerator will be removed before proceeding.
Strategy - Vectorizing
Following queues from the Data Vectorizing - NewsAPI page, this initial pass will lemmatize the data and use CountVectorizer() from the scikit-learn library, and compare the different aggregation schemas. The TfidfVectorizer() could be invaluable in later use cases, as the length of the text content for many of the Reddit aggregation schemas vary wildly.
Lemmatizing is still a useful data dimensionality reduction technique. However, when it comes to Reddit posts, lemmatizing and especially stemmatizing should be used cautiously. News articles mostly use proper and accepted language, structure, and terms, whereas social media and other online community discussion boards, like Reddit, are likely to follow a more unofficial format. Social media may feature slang, text speak, mispellings, and incomplete sentences. Incomplete sentences could be due to single word responses or reactions, or simply due to improperly structured sentences. Nuances in Reddit-type posts could be lost with cleaning and simplification methods.
Additionally, stopwords will be removed and 200 maximum features will be used.
Vectorizing - Thread-Author Schema
| author | url | subreddit | search | able | account | actually | administration | ago | american | aren | away | bad | balance | bank | bankruptcy | based | believe | benefit | best | better | biden | big | borrower | business | buy | car | card | care | career | case | change | class | college | come | company | congress | cost | country | court | credit | day | debt | decision | degree | democrat | did | didn | different | doe | doesn | doing | dollar | don | education | end | exactly | federal | feel | financial | forgive | forgiven | forgiveness | free | fuck | future | getting | going | good | got | government | graduate | great | ha | happen | hard | having | help | high | higher | home | hope | house | idea | idr | income | instead | isn | issue | job | just | kid | know | law | le | left | let | life | like | likely | loan | lol | long | look | lot | low | lower | major | make | making | maybe | mean | million | minimum | mohela | money | month | monthly | mortgage | need | new | number | old | paid | parent | party | pay | paying | payment | people | person | plan | point | poor | ppp | predatory | president | pretty | price | principal | private | probably | problem | program | pslf | public | rate | real | really | reason | repayment | republican | rich | right | said | save | say | saying | school | score | service | shit | start | started | state | stop | student | sure | taking | tax | term | thing | think | thought | time | took | total | trump | try | trying | tuition | understand | university | use | used | ve | vote | wa | want | way | went | won | work | worked | working | wouldn | yeah | year | yes | zero |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Wordcloud
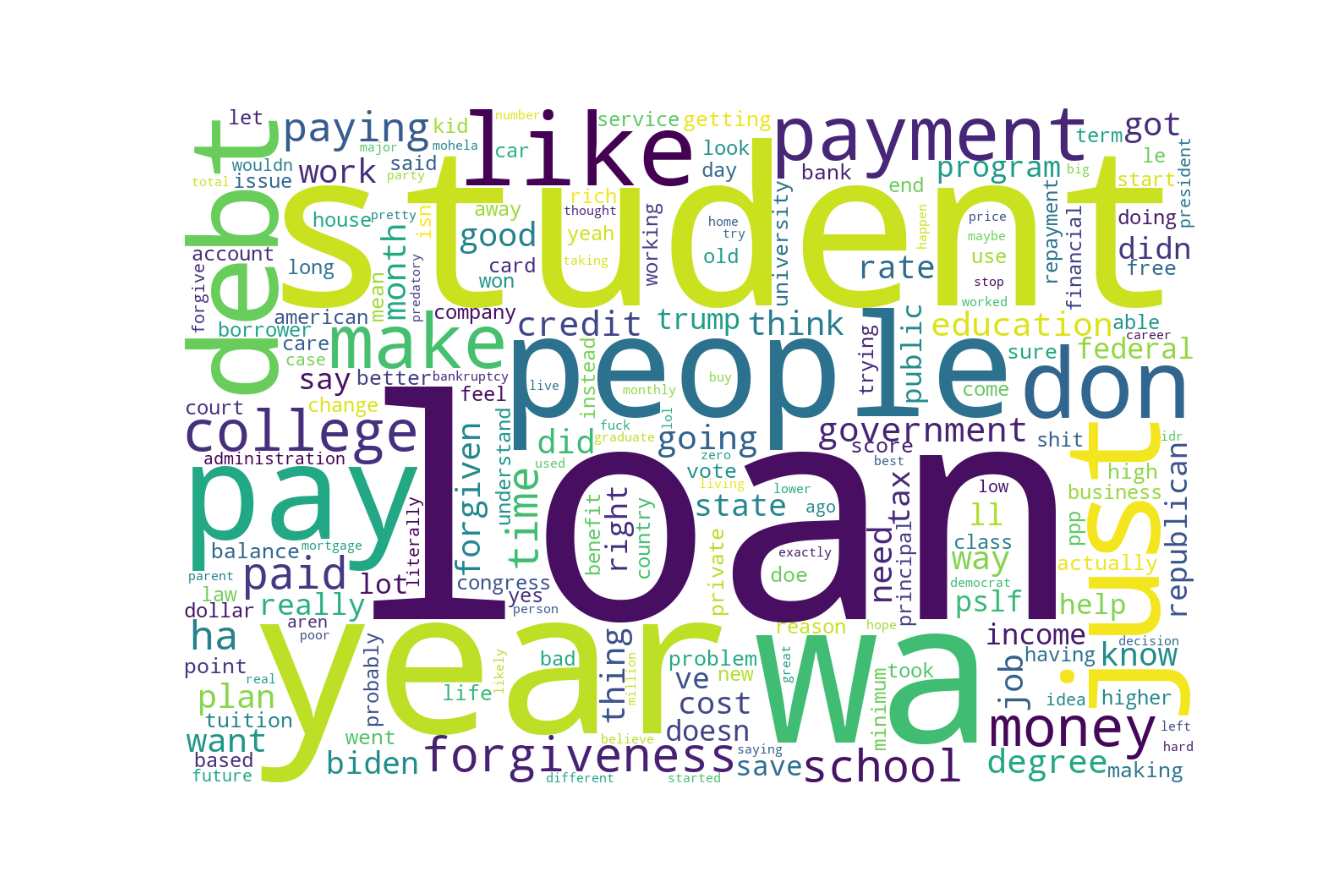
Most Frequent Words
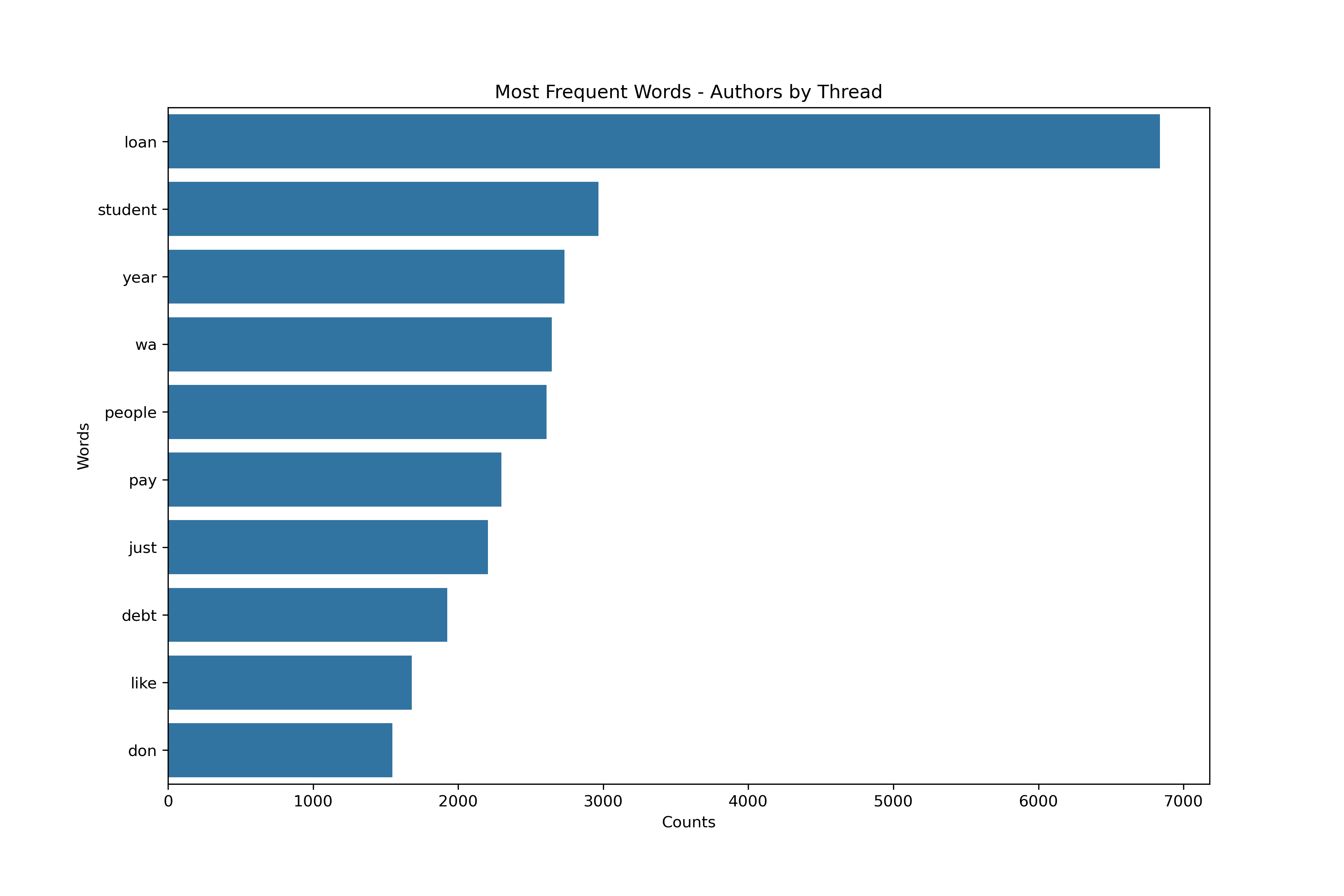
Vectorizing - Subreddit-Author Schema
| author | subreddit | able | account | actually | administration | ago | american | aren | away | bad | balance | bank | bankruptcy | based | believe | benefit | best | better | biden | big | borrower | business | buy | car | card | care | career | case | change | class | college | come | company | congress | cost | country | court | credit | day | debt | decision | degree | democrat | did | didn | different | doe | doesn | doing | dollar | don | education | end | exactly | federal | feel | financial | forgive | forgiven | forgiveness | free | fuck | future | getting | going | good | got | government | graduate | great | ha | happen | hard | having | help | high | higher | home | hope | house | idea | idr | income | instead | isn | issue | job | just | kid | know | law | le | left | let | life | like | likely | literally | live | loan | lol | long | look | lot | low | lower | major | make | making | maybe | mean | million | minimum | mohela | money | month | monthly | mortgage | need | new | number | old | paid | parent | party | pay | paying | payment | people | person | plan | point | poor | ppp | predatory | president | pretty | price | principal | private | probably | problem | program | pslf | public | rate | real | really | reason | repayment | republican | rich | right | said | save | say | saying | school | score | service | shit | start | started | state | stop | student | sure | taking | tax | term | thing | think | thought | time | took | total | trump | try | trying | tuition | understand | university | use | used | ve | vote | wa | want | way | went | won | work | worked | working | wouldn | yeah | year | yes | zero |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Wordcloud

Most Frequent Words
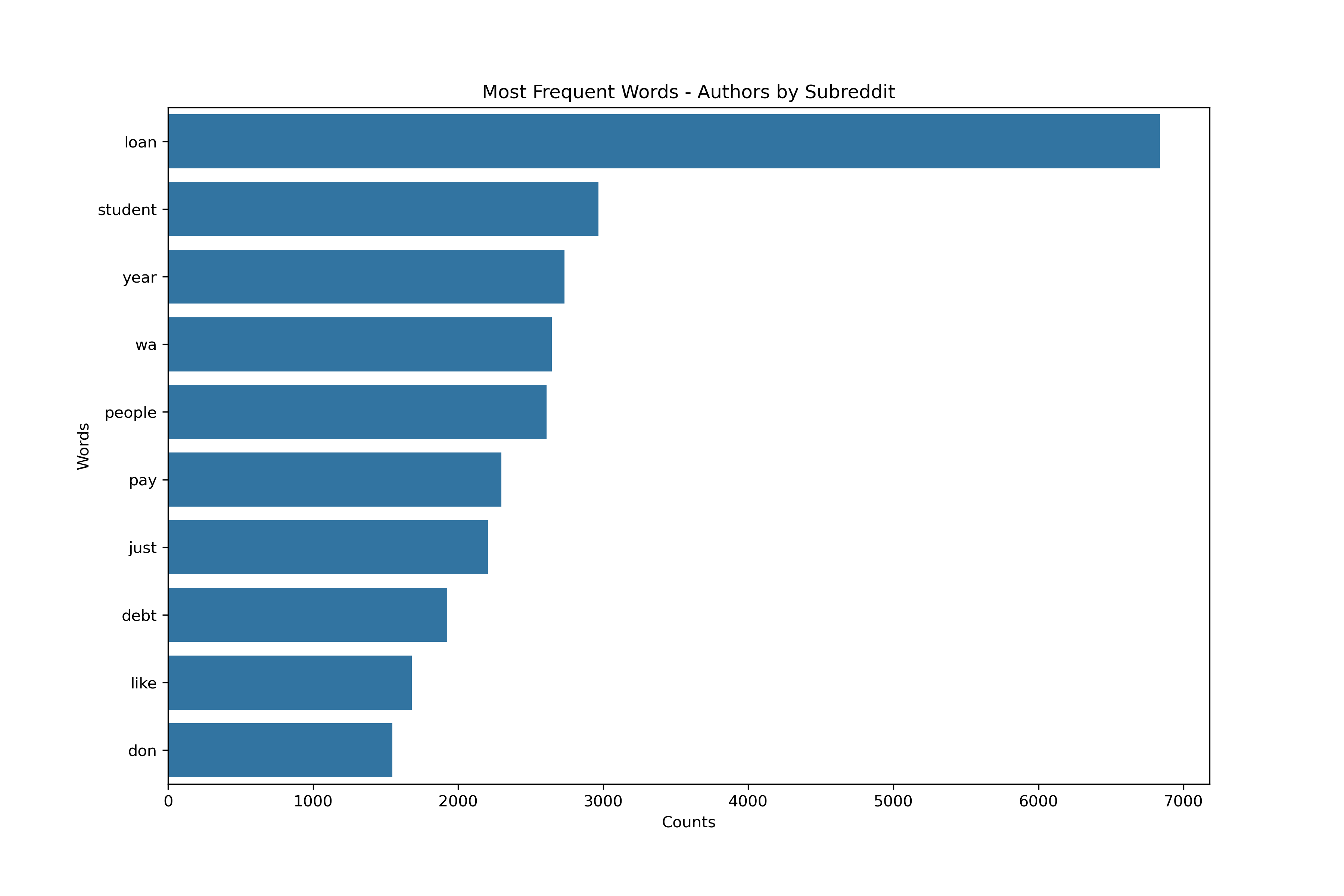
Vectorizing - Threads Schema
| url | able | account | actually | administration | ago | american | aren | away | bad | balance | bank | bankruptcy | based | believe | benefit | best | better | biden | big | borrower | business | buy | car | card | care | career | case | change | class | college | come | company | congress | cost | country | court | credit | day | debt | decision | degree | democrat | did | didn | different | doe | doesn | doing | dollar | don | education | end | exactly | federal | feel | financial | forgive | forgiven | forgiveness | free | fuck | future | getting | going | good | got | government | graduate | great | ha | happen | hard | having | help | high | higher | home | hope | house | idea | idr | income | instead | isn | issue | job | just | kid | know | law | le | left | let | life | like | likely | literally | live | living | loan | lol | long | look | lot | low | lower | major | make | making | maybe | mean | million | minimum | mohela | money | month | monthly | mortgage | need | new | number | old | paid | parent | party | pay | paying | payment | people | person | plan | point | poor | ppp | predatory | president | pretty | price | principal | private | probably | problem | program | pslf | public | rate | real | really | reason | repayment | republican | rich | right | said | save | say | saying | school | score | service | shit | start | started | state | stop | student | sure | taking | tax | term | thing | think | thought | time | took | total | trump | try | trying | tuition | understand | university | use | used | ve | vote | wa | want | way | went | won | work | worked | working | wouldn | yeah | year | yes | zero |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Wordcloud
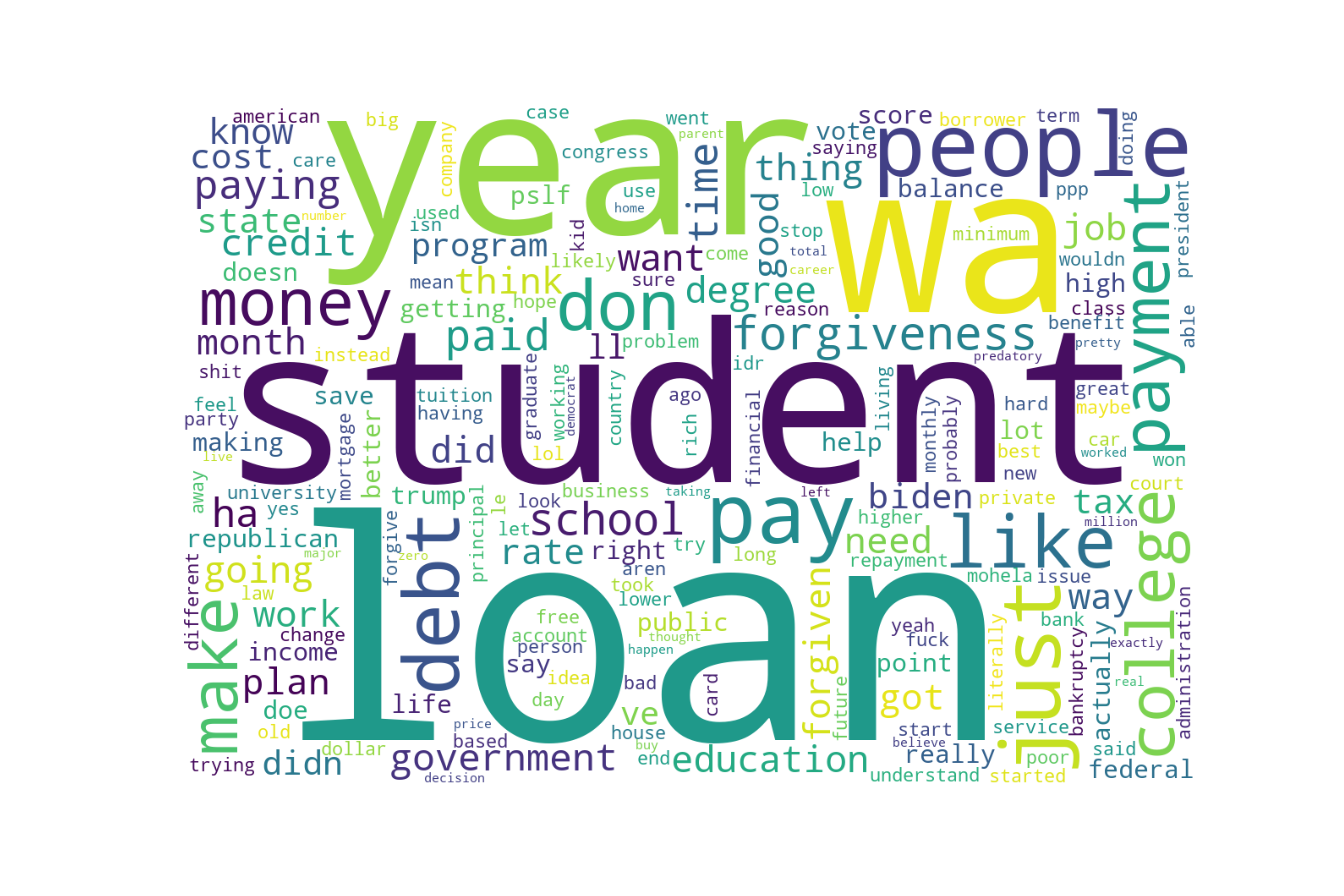
Most Frequent Words
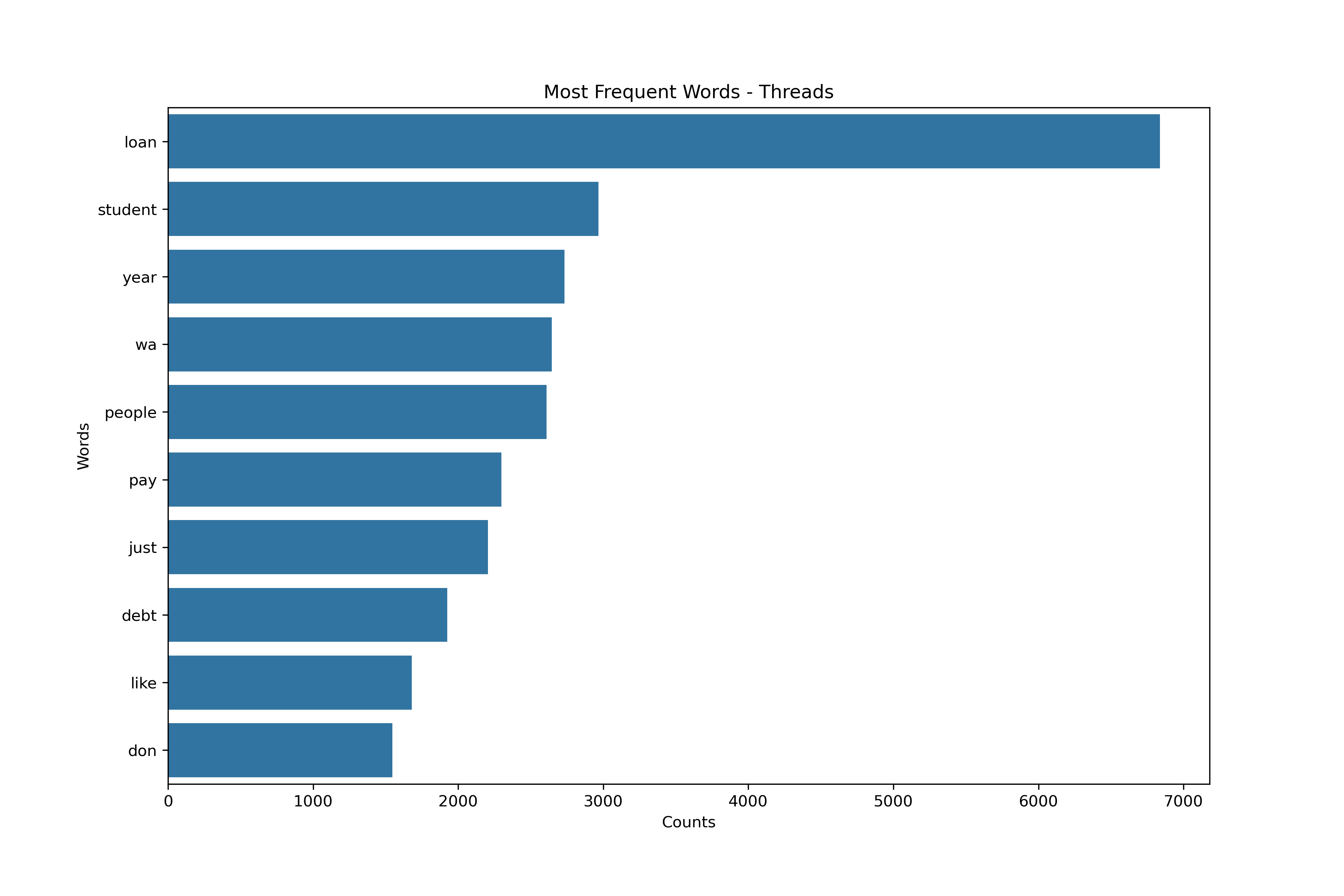
Vectorizing - Subreddits Schema
| subreddit | able | account | actually | administration | ago | american | aren | away | bad | balance | bank | bankruptcy | based | believe | benefit | best | better | biden | big | borrower | business | buy | car | card | care | career | case | change | class | college | come | company | congress | cost | country | court | credit | day | debt | decision | degree | democrat | did | didn | different | doe | doesn | doing | dollar | don | education | end | exactly | federal | feel | financial | forgive | forgiven | forgiveness | free | fuck | future | getting | going | good | got | government | graduate | great | ha | happen | hard | having | help | high | higher | home | hope | house | idea | idr | income | instead | isn | issue | job | just | kid | know | law | le | left | let | life | like | likely | literally | live | living | loan | lol | long | look | lot | low | lower | major | make | making | maybe | mean | million | minimum | mohela | money | month | monthly | mortgage | need | new | number | old | paid | parent | party | pay | paying | payment | people | person | plan | point | poor | ppp | predatory | president | pretty | price | principal | private | probably | problem | program | pslf | public | rate | real | really | reason | repayment | republican | rich | right | said | save | say | saying | school | score | service | shit | start | started | state | stop | student | sure | taking | tax | term | thing | think | thought | time | took | total | trump | try | trying | tuition | understand | university | use | used | ve | vote | wa | want | way | went | won | work | worked | working | wouldn | yeah | year | yes | zero |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Wordcloud

Most Frequent Words
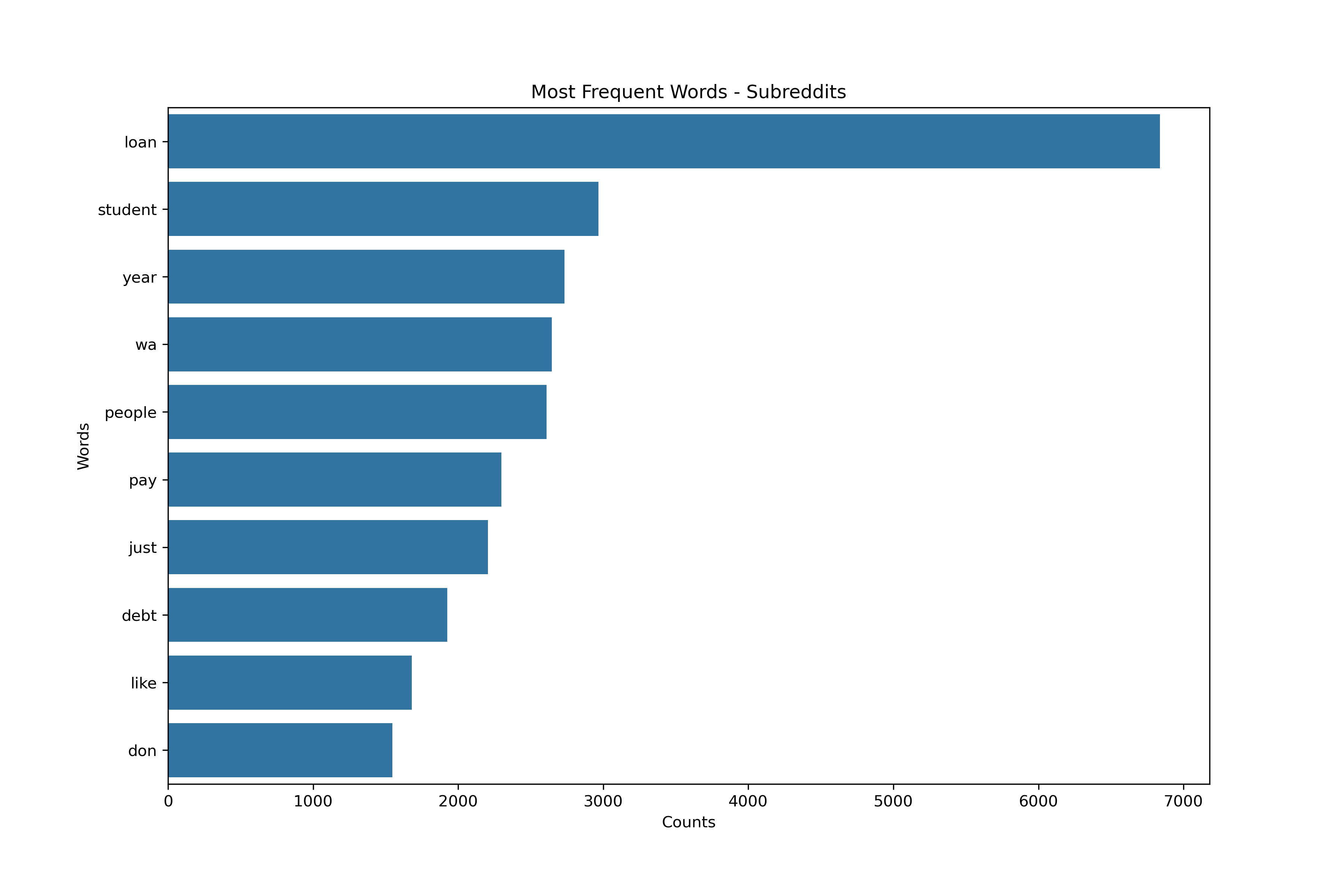
Vectorizing - Authors Schema
| author | able | account | actually | administration | ago | american | aren | away | bad | balance | bank | bankruptcy | based | believe | benefit | best | better | biden | big | borrower | business | buy | car | card | care | career | case | change | class | college | come | company | congress | cost | country | court | credit | day | debt | decision | degree | democrat | did | didn | different | doe | doesn | doing | dollar | don | education | end | exactly | federal | feel | financial | forgive | forgiven | forgiveness | free | fuck | future | getting | going | good | got | government | graduate | great | ha | happen | hard | having | help | high | higher | home | hope | house | idea | idr | income | instead | isn | issue | job | just | kid | know | law | le | left | let | life | like | likely | literally | live | living | loan | lol | long | look | lot | low | lower | major | make | making | maybe | mean | million | minimum | mohela | money | month | monthly | mortgage | need | new | number | old | paid | parent | party | pay | paying | payment | people | person | plan | point | poor | ppp | predatory | president | pretty | price | principal | private | probably | problem | program | pslf | public | rate | real | really | reason | repayment | republican | rich | right | said | save | say | saying | school | score | service | shit | start | started | state | stop | student | sure | taking | tax | term | thing | think | thought | time | took | total | trump | try | trying | tuition | understand | university | use | used | ve | vote | wa | want | way | went | won | work | worked | working | wouldn | yeah | year | yes | zero |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Wordcloud

Most Frequent Words
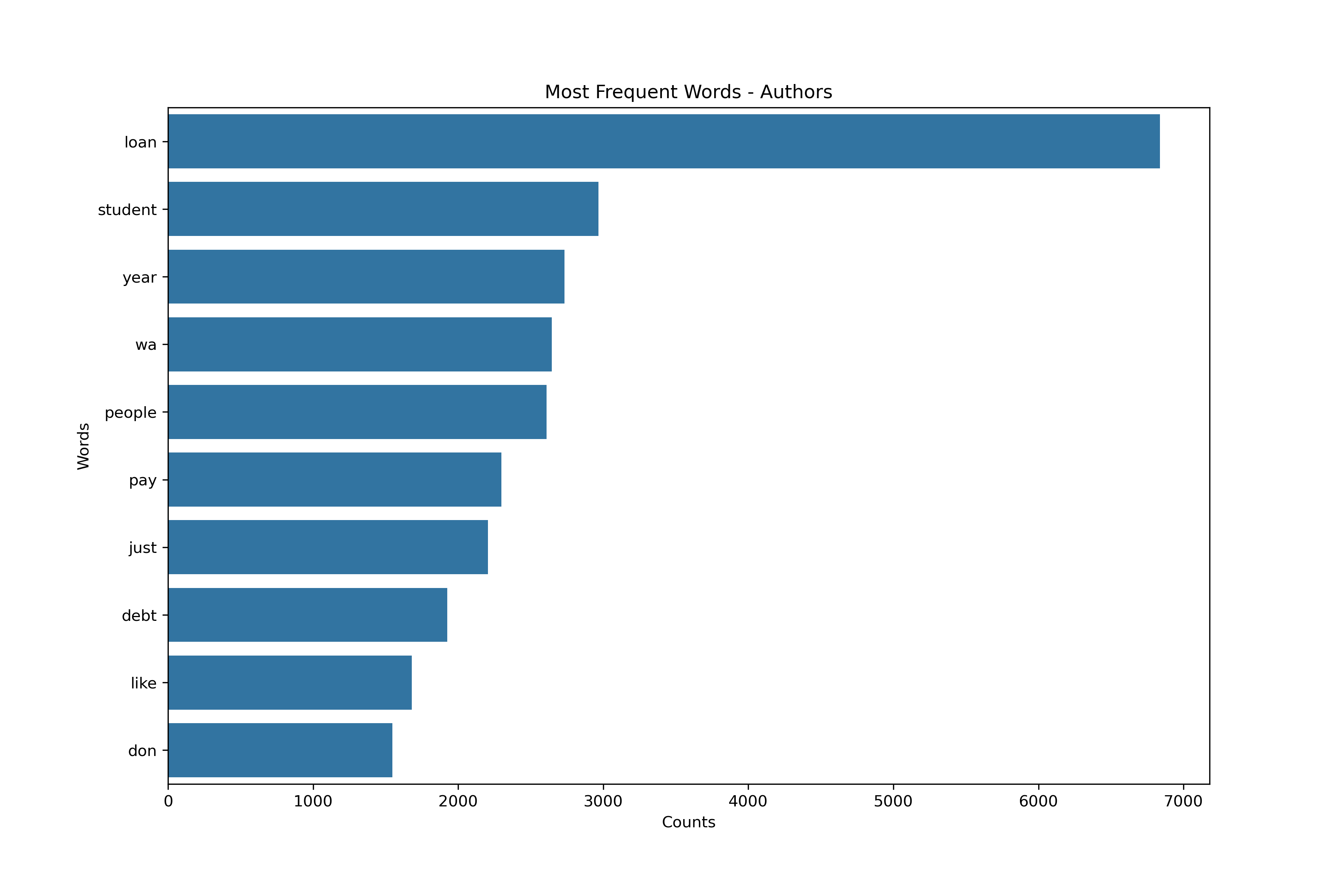
Vectorizing - Additional Parameters
| author | url | subreddit | search | debt | don | just | like | loan | make | pay | people | student | wa | year |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loading ITables v2.3.0 from the internet... (need help?) |
Wordcloud

Most Frequent Words
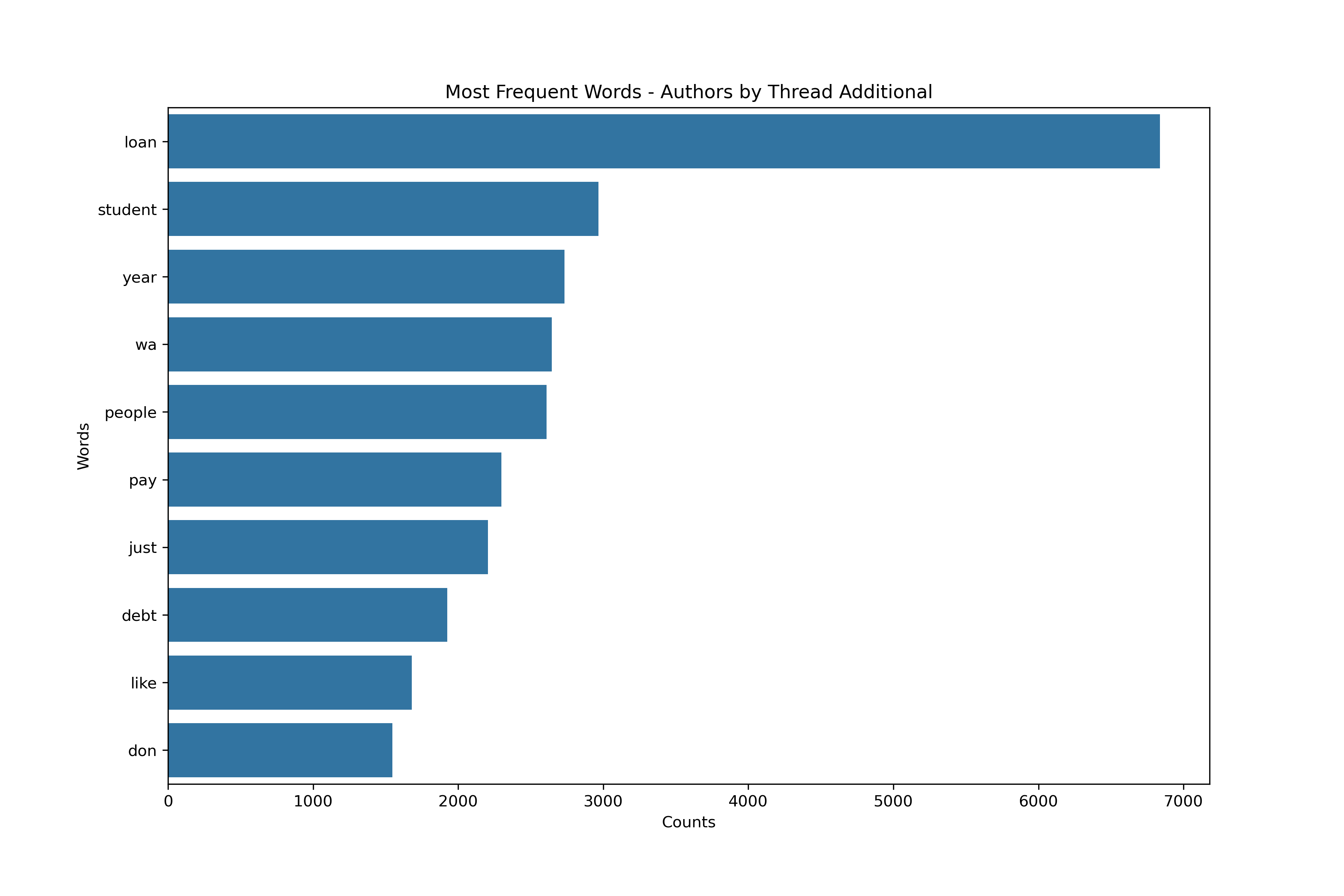
Summary
With the initial pass above, there are very minor differences between the aggregation schemas and respective corpuses. Stronger differences would likely be found if further subsetting on the authors, threads, and Subreddits. In future analyses, unsupervised learning methods and potentially supervised learnings methods (when paired with NewsAPI) could help indicate these subsets. Furthermore, pairings from upvotes and length of content within the data could be potential subsetting parameters as well.
However, when taking away the maximum features parameter and then restraining the data from a minimum frequency of \(0.1\) and a maximum frequency of \(0.9\) reveals a much different wordcloud. The range is rather large, but there are a limited number of words.
Code Links
- Vectorizing Script: functions for the vectorization process
- Reddit Vectorizing Script: application of Vectorizing Script